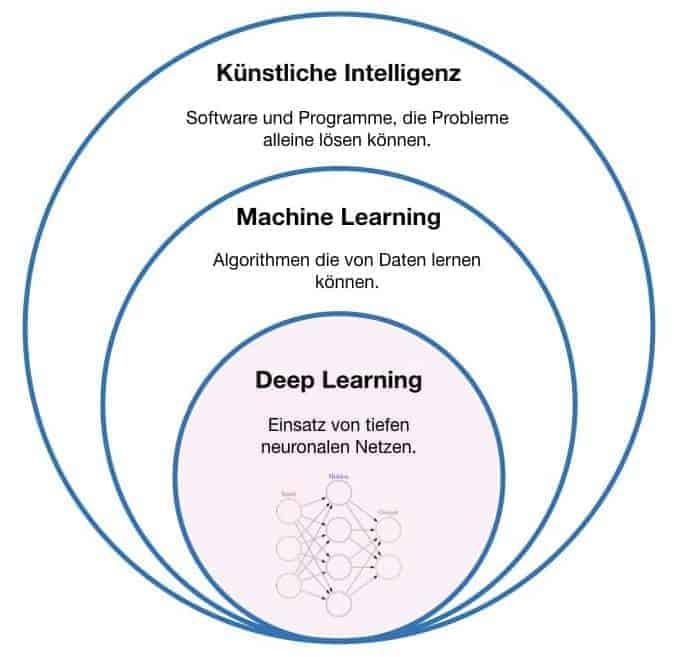

Derzeit fehlt Anwendern meist noch die Erfahrung, welcher der zahlreichen KI-Lösungen für ihre Aufgabenstellung die Richtige ist. Daher hat inVISION bei Cubemos, EvoTegra, MVTec und Ruhlamat nachgefragt, worauf man bei der Auswahl der richtigen KI-Lösung achten sollte.
inVISION: Wo liegen die Unterschiede zwischen den verschiedenen Deep Learning Tools?
Tobias Manthey (EvoTegra): Für uns hängt die Auswahl von den folgenden Kriterien ab: welche Modelle werden unterstützt und welche Integrationsmöglichkeiten gibt es für den professionellen Einsatz (C++, TensorRT). Grundsätzlich muss man beachten, dass Open Source Deep Learning Frameworks aus der Forschung kommen und für die Forschung angedacht sind, d.h. Stabilität, Übertragbarkeit auf reale Anwendungen und Bedienbarkeit sind keine Kriterien für die Entwicklung. Die meisten Open Source Deep Learning Frameworks stellen im Prinzip Anwendungen im Alpha Status dar.
 die Probleme beim Deep Learning?")
Dr. Christopher Schweubel (Cubemos): Wir nutzen primär TensorFlow und PyTorch. Beides sind gute Frameworks um neuronale Netze zu trainieren und auf der Zielhardware zu implementieren. Die Zielhardware bestimmt meist, welches Framework wir verwenden, jedoch wird die Interoperabilität immer besser.
Mario Bohnacker (MVTec): Wenn man die verschiedenen Deep Learning (DL) Produkte vergleicht, stellt man fest, dass sie sich in ihrer Performance hinsichtlich der reinen Klassifikationsergebnisse oftmals gar nicht allzu sehr unterscheiden. Allerdings gibt es einen immensen Unterschied bei den DL-Produktmerkmalen, wenn man sich nicht nur das reine Klassifikationsergebnis ansieht. Ein Beispiel hierfür ist, wie DL-Algorithmen in industrielle Applikationen integriert bzw. wie schnell neue DL-Methodiken mit bestehender BV-Algorithmik kombiniert werden können? Ein weiterer Aspekt ist, wie die DL-Funktionalität für die Anwendungserstellung nutzbar gemacht wird (Programmieren vs. Konfigurieren), sowie ob zwischen verschiedenen Open-Source-Tools hin und her gewechselt werden muss, oder ob es sich um eine Gesamtlösung aus einer Hand handelt. Letzteres bringt eine gewisse Nachhaltigkeit und Langzeitverfügbarkeit mit sich. Bisher werden für DL-Anwendungen hauptsächlich GPUs eingesetzt. Es besteht jedoch auch eine Nachfrage zum Einsatz von DL auf IPCs, die keine Grafikkarte haben oder auf Arm-basierten Systemen. Der Markt für spezifische DL-Hardware ist derzeit sehr schnelllebig und ausdifferenziert, weshalb wir aktuell an einer generischen Möglichkeit arbeiten, Hardware-Beschleuniger zukünftig schnell in Halcon nutzbar zu machen.
Florian Weihard (Ruhlamat): The various DL tools can be mapped on two axes – complexity versus flexibility. With a high degree of flexibility comes greater complexity, and hence requires a specialized skillset of a data scientist. With low complexity comes some rigidity in applications or unsuitability or inaccuracies in a model that is developed. There are DL tools – mainly ’no-code‘ model training environments – that provide an extremely simple user interface that can train a very generic model. This results in the pitfall that the model that is trained is not particularly useful for its actual application. In case of industrial applications, it is always more helpful to have a model that is trained for a specific purpose rather than a generic model. Our EaglAI uses models that were initially developed for identifying features in satellite imagery, to do defect detection on injection moulded parts. This is because the two applications have a similarity in that they are trying to find a very tiny feature in a large image. There are also model execution frameworks available, mainly on cloud which are trickier to use. In industrial applications, a cloud-based solution is more likely to be an unsuitable solution, often replaced by on premise and offline execution systems. The model execution frameworks also tend to be very specific to the model type that it is designed to use – the outputs can vary (e.g. between classification models and object detection models), the underlying dependencies can also vary (e.g. between TensorFlow and PyTorch), and their hardware / computational requirements can also vary.
Seiten: 1 2 3Auf einer Seite lesen








Tipps, um Ihre elektrische Installa...
Maintal wird durch neue WLAN-Hotspo...
Unternehmen im Kreis Pinneberg : Wa...
Neue U-Bahn-Werkstatt und -Waschhal...